오늘은 잠깐잠깐 시간도 나고, 테이블 가지고 지지고 볶고 하다 보니까 옛날 생각도 나서 끄적여 봅니다. 전산 계통에 관심없는 분은 패쓰~ ^^;;;
옛날에 DataBase가 등장하기 전에는 ISAM 파일 정도가 DataBase 개념에 가장 가까웠습니다. 단순 Text 파일로도 한줄씩 읽어가면 찾기도 했지만, ISAM은 대용량 자료 검색시에 Key 값만 알면 월등한 속도로 검색을 해 줬으니까요.
그래서 지금같은 RDB(Relation DataBase)가 등장하기 전과 RDB가 성숙하기 전에 대용량 데이터 베이스는 백이면 백 ISAM의 변종이었습니다. ISAM, OSAM, VSAM 등등. 물론 그런 대용량 DataBase를 운용하는 머신은 IBM 같은 벤더의 Main Frame 이었고요.
입사 전에 당시 PC용 ISAM 엔진 C 라이브러리를 정품으로 구매해서 사용 중이었기 때문에, IBM의 VSAM 기반 DataBase가 낯설지는 않았습니다. 개념은 ISAM이나 다른 인덱스드 샘 파일 변종이나 같으니까요.

이게 당시 가장 표준적인 IBM의 IMS-DB/DC를 이용해서 사용되는 DB의 모습입니다.
RDB 개념으로 보면 [창고 테이블]과 [저장위치 테이블]의 개념적 종속관계입니다. 물론 Foreign Key로 두개를 묶어 둘 수도 있겠고요. 아무튼 각각에 대해서 create table로 생성을 합니다.
그러나 Hierarchy DB는 DB 생성시에 저런 레벨(종속관계)를 모두 기술해서 한번에 생성합니다. 각각 별개의 DB가 아니라, 한 DB에 레벨이 2개 존재하게 됩니다. 그리고 그림의 빨간 화살표는 각각의 노드를 잇는 Pointer 입니다. DB의 Key를 완전히 알고 있다면 수억건의 Node가 있는 DB라도 0.0x 초 단위로 검색되서 나오게 되지만, Key를 Full로 알지 못하면 비슷한 놈 하나를 검색해서, 거기부터 순차적으로 저 Pointer를 따라 Tree 운행을 시작하게 됩니다. 전형적인 Tree 운행 순서인데, 순방향 Pointer 외에 역방향 Pointer도 만들건지는 Hierarchy DBD 생성 스크립에 기술하기 나름이고요.
이렇게해서 Hierarchy DB 란 녀석은 잘 움직이는데 장점과 단점이 함께 있었습니다.
장점은 대단히 빠른 검색 속도입니다.
Data 양과 거의 무관할 정도로 Key 정보를 부여할 수 있으면, 지금도 슈퍼 돔급 서버 클러스터링한것 보다 빠릅니다. 속도는 짱~
또 실시간 Data Compaction 이 가능해서, Key 부분을 제외한 데이타 부분은 1/2 수준으로 자료가 압축되어 디스크에 저장됩니다. 거기에 써드파티 BMC 같은 유틸리티를 적용하면 압축율은 Key를 포함해서 1/10 수준으로 뚝...
그리고 장점 끝... -_-;;;
단점은 무궁무진했습니다. -_-;;;
우선 컬럼이라는 개념이 없습니다. 각 레벨에 대해서 스크립트를 만들때 총 segment의 바이트 숫자, 그 중에 Key 부분의 byte 숫자만 기술을 하니까요.
예를 들면 aaaaa란 segment는 100byte의 크기를 갖고, Key부분은 30byte를 차지한다. 이게 스크립트의 끝입니다. 당연히 segment를 프로그램은 structure에 통으로 전달받고, structure에 구분된 변수 항목별로 알아서 기어 들어간 데이타를 구분해 읽는 방식입니다. 물론 include용 structure 만 잘 관리되면 문제없는데.. 만든지 오래된 DB는 꼭 저 structure 정보를 분실해서, DB는 멀쩡히 동작하는데 데이타 조합을 못해서 애먹는 경우가 생기곤 합니다. -_-;;;
그리고 Pointer가 깨지면 DB는 생명이 끝입니다. 예를 들어서 DB를 On0Line 서비스 중에 CheckPoint 라는 온라인 갱신 방법을 적용하지 않고, Batch 프로그램으로 갱신하면.. 그 순간 Pointer가 다 날아 갑니다. 복구는... 사실상 불가능합니다. 디스크에 압축된 상태로 데이타가 보관되어 있어서, 디스크 Image를 띄워 올려도 알아 먹을 방법이 없으니까요. BMC 같은 유틸리티를 적용하지 않은건 그나마 압축 알고리즘이 알려져 있어서, 꾸역꾸역 복구하는 경우도 있기는 했습니다. 복구 마치면 청량리 정신병원으로 고고싱.. -_-;;
그러나 가장 큰 단점은 DB 설계를 아무나 할 수 없다는 점이었습니다. Key의 오름차순으로만 다음 노드를 읽을 수 있기 때문에, Key 자체의 무결성도 중요하지만 가장 빈번한 검색 및 정렬 조건을 모두 감안해서 설계가 되야 하기 때문입니다. (물론 Secondary Key를 덧붙이면 되긴하지만, 치명적일 정도로 속도 저하, 관리 곤란..)
그래서 Hierarchy DB는 입사하고 실무 경력이 5년 이하면 손도 못 대는 일이었던 기억이 납니다. DB의 개념을 아는것과는 별개로 실제 사용자의 업무를 모르고는 DB 설계가 아예 불가능하니까요. 저도 5년 좀 안되서 DB 설계를 단독으로 했던것 같네요.
그 외에도 소소한 장단점이 추가로 있지만, 저 단순 무식한 대용량 DataBase가 RDB로 바뀐건 21세기가 되서야 조금씩 바뀌었습니다. 제가 담당하던 업무도 억단위 Node를 가진 수많은 DB를 오라클로 전환한건 몇년 안 된 일이고요.
요새는 저 Hierarchy DB 쓰던 시절이 생각도 나고, 그립기도 하고 그렇습니다. 한번 조져 놓으면 뒷감당 안되는거 전산 담당자나 실무자나 서로 알고, 신중히 설계해서 꾸역꾸역 사용하던 시절이 그립네요. 언제 내게 DB 설계해도 된다는 명령이 떨어지나 학수고대하던 것도 좀 그립기도...
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ





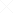

 제목
제목


